
N-Body 1.18
Message boards :
News :
N-Body 1.18
Message board moderation
Previous · 1 · 2 · 3 · 4 · Next
| Author | Message |
|---|---|
|
Send message Joined: 4 Sep 12 Posts: 219 Credit: 456,474 RAC: 0 |
I'm not quite sure what you're referring to as 'resource monitor', but probably the best tool (on Windows) for checking multi-thread usage is Process Explorer. Here it is monitoring ps_nbody_06_06_nodark_3_1370577207_73813 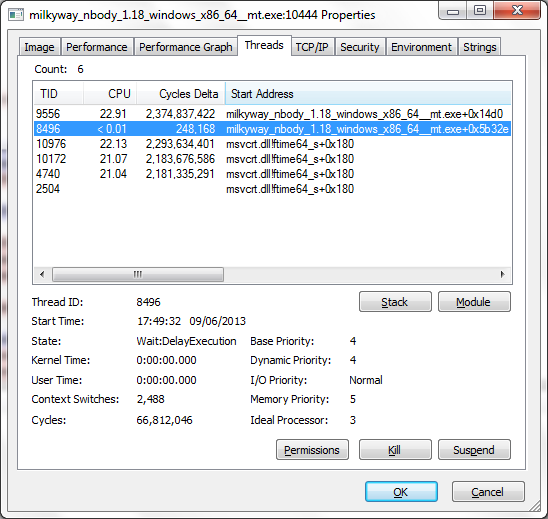 All is well - that's how it should look on a four-core CPU. That was 'nodark' - I've got a 'dark' to test now, so I'll keep an eye on it. |
|
Send message Joined: 4 Sep 12 Posts: 219 Credit: 456,474 RAC: 0 |
A possible explanation - my first couple of 'dark' tasks were issued with the non-multithreaded plan-class. Check that the tasks being watched have '(mt)' visible, either in BOINC Manager or the extreme-right column in views like All tasks for computer 479865 Edit - ps_nbody_06_06_dark_1370577207_123338 (mt) is running fully multithreaded for me - I won't bother with an image, it's the same as last time. |
|
Send message Joined: 26 May 11 Posts: 32 Credit: 47,728,352 RAC: 77 |
I have checked and am certain all jobs were marked as dark and mt that I was referencing. Furthermore, the second dark mt job just started that did fully utilize all 12 processors. However it's estimated run time is +30 minutes. All of the other dark nt jobs that did not fully deploy all processors were from 1 to 10 minutes. Furthermore, I did check my tasks out, and found most of short dark mt jobs have CPU time +/- equal to run time seconds. I would have expected to see CPU seconds = to something like 10 * run time. Just to continue the same thread... the long dark task above just finished. a short dark just started, 6 of 12 CPU's are "parked", then other 6 are deployed at low run rates. The short dark mt finished, a 1+ hour dark mt task just started, and is functioning as expected. I would recommend the checks need to focus on short dark jobs, as perhaps not all the different multi threads need to be engaged. Suggestion, have the system admin run a query on the database to return work units where: tasks types contain mt, and CPU time < runtime * 1.2 |
|
Send message Joined: 4 Sep 12 Posts: 219 Credit: 456,474 RAC: 0 |
I've broken my old record. I've got a 100k_chisq_alt which is estimated at 35062:56:00 - over FOUR years this time. What's more, it is set to run MT, so it actually wants 16 CPU-years. Within a 12-day deadline, that's a tough ask. Since the MT scheduler prevents any other CPU task from other projects running at the same time (we need to have a talk about this), this over-estimation and short deadlines is very un-neighbourly (a word I think I've used before). We'll see how this one goes, but after that I think the time will quickly come for some reality-checking. |
|
Send message Joined: 26 May 11 Posts: 32 Credit: 47,728,352 RAC: 77 |
More observations... I have yet to see one of these x,xxx hour jobs actually go over 1 hour actual run time. And But, a strange thing often does happen at 98% complete... I also have 2 NVidia GPU cards running tasks for Siti astropulse. At 98% the nbody task stops running and want 100% of my cpu's which includes the .2 CPU's of the Siti astorpulse jobs NVidia jobs running. I have to manually stop - suspend all NVidia tasks on the computer until the nbody mt task finishes which is actuall less then 2 minutes actual time (etimated at xxx.xx hours). Bottom line, these tasks run, but take monitoring & active involement action by the host operator otherwise the computer essential goes into a stall mode... |
|
Send message Joined: 26 May 11 Posts: 32 Credit: 47,728,352 RAC: 77 |
morning here, I checked my tasks from last night, some 100 mt tasks ran since 10Jun UTC, and find about 20% of them have run time = +/- CPU time. All of these tasks that I checked are mt dark. |
|
Send message Joined: 4 Sep 12 Posts: 219 Credit: 456,474 RAC: 0 |
More observations... I have yet to see one of these x,xxx hour jobs actually go over 1 hour actual run time. And But, a strange thing often does happen at 98% complete... I also have 2 NVidia GPU cards running tasks for Siti astropulse. At 98% the nbody task stops running and want 100% of my cpu's which includes the .2 CPU's of the Siti astorpulse jobs NVidia jobs running. I have to manually stop - suspend all NVidia tasks on the computer until the nbody mt task finishes which is actuall less then 2 minutes actual time (etimated at xxx.xx hours). Just seen exactly the same thing - long task, got pre-empted by BOINC when it eventually dropped out of high priority (at 99.710% complete). Won't restart while a GPU task is running, even one just claiming 0.04 CPUs - the log says "avoid MT overcommit". That's a BOINC client scheduling bug - I've reported it with evidence to the boinc_alpha mailing list. |
|
Send message Joined: 4 Sep 12 Posts: 219 Credit: 456,474 RAC: 0 |
Continued Observations: So far AS I HAVE OBSERVED only 1 dark mt job has utilized all 12 cores. All of the short jobs - estimated at less than 10 minutes have all have many cores "parked". The one dark mt job that used all cores had an estimated time in the 0'000 hours, and took say 45 minutes to run... Picking one of these messages at random for an observation. Watching a few MT tasks (short ones) run through to completion. They seem to reach 100% progress, then stay 'Running' at 100% for a while. Checking with process explorer, what seems to be happening is that most of the threads finish whatever their job was, and just one thread is still chugging away - I'm wondering if this might be what jdzukley is seeing? The big trick with multithreaded programming is to give all the threads the same amount of work to do, so they all finish together (or to keep doing some sort of thread synchronisation to keep them in step as the run progresses). This is particularly true in the BOINC MT environment where the CPUs which have finished their allotted work aren't released back into the pool for re-assignment until the last laggard slowcoach has finished. |
|
Send message Joined: 4 Apr 13 Posts: 3 Credit: 572,285 RAC: 0 |
Just to expand a little, when the mt job parks at ready to start at about 99% it is necessary to suspend all the other queued jobs as they start one after the other, then the mt finishes. |
|
Send message Joined: 26 May 11 Posts: 32 Credit: 47,728,352 RAC: 77 |
yes, and but on my computer for mt dark tasks estimated at less then 10 minutes, 6 of 12 CPU's are parked for the entire duration of the task. Also, look at run time verses CPU time +/- equal in the results file. Why does the above group of tasks always have this condition! Bottom line the above referenced group of tasks are executing very ineffectively, perhaps with correct results, and are reserving 1100% more resources meaning only 1 CPU is required, and 12 CPUs are reserved for the entire run time! also note that actual run time is most often 5 to 8 times (*) > original estimated run time. In other words, if MT was really working on the above group, the original estimate is ok. |
|
Send message Joined: 26 May 11 Posts: 32 Credit: 47,728,352 RAC: 77 |
posted twice, need to eliminate this one, do not see the delete button, might need new eye glasses or reading lessons... |
|
Send message Joined: 26 May 11 Posts: 32 Credit: 47,728,352 RAC: 77 |
FYI, I just noticed that during the last 48 hours, I have 5 mt dark tasks long runs that have error out after reaching 100%... When looking at the work unit details indicate that they are erring for others too with "Too many errors (may have bug)" message... |
|
Send message Joined: 20 Aug 12 Posts: 66 Credit: 406,916 RAC: 0 |
That is strange. I am pulling this run down. Jake |
|
Send message Joined: 4 Sep 12 Posts: 219 Credit: 456,474 RAC: 0 |
That is strange. I am pulling this run down. Would you still like my attempt at http://milkyway.cs.rpi.edu/milkyway/workunit.php?wuid=372074737, since it isn't in the afected group? Better to abort it before it starts on the 3.5 year odyssey, if you don't want it, but I'm happy to let it run. |
|
Send message Joined: 20 Aug 12 Posts: 66 Credit: 406,916 RAC: 0 |
Can someone please let me know if the process is still running after it gets stuck at 98%? Thanks, Jake |
|
Send message Joined: 26 May 11 Posts: 32 Credit: 47,728,352 RAC: 77 |
If you have a Graphics card, you must manually shut down "suspend" all graphics jobs and wait for a few moments for the mt task to complete. As soon as the mt task completes restart all graphics jobs. Note you must hold ALL graphic card jobs, not just the current jobs running. The error was noted below and turned in as a problem. for the few MT tasks that did this, they all had something OTHER than dark or nodark in the task name, and all had estimated run times in the thousands (xxxx. hours) and all arrived at 98% after about 1 hour run time. |
 Jeffery M. Thompson Jeffery M. Thompson Send message Joined: 23 Sep 12 Posts: 159 Credit: 16,977,106 RAC: 0 |
For the people having the tasks lock with gpu tasks also in their scheduler. Is this only happening to people running Boinc Version 7.0.64? If you are getting this problem and using a different version of Boinc please let us know the version. All of the users reporting it in here have that as there version of Boinc which Richard reported as bug to the alpha mailing list. Jeff |
|
Send message Joined: 4 Sep 12 Posts: 219 Credit: 456,474 RAC: 0 |
Can someone please let me know if the process is still running after it gets stuck at 98%? Rather depends what you - and they - mean by 'get stuck'. What I saw at 99.710% was a perfectly normal "no longer needs to run in high priority" (not in danger of missing deadline), so BOINC gave it a rest and gave other projects' work a chance to run, to balance resource share. I didn't explicitly check that all threads had suspended when BOINC told it to get out of the way - I will do next time - but I didn't notice any of the replacements running slow. |
|
Send message Joined: 21 Dec 12 Posts: 1 Credit: 5,304,828 RAC: 0 |
I have two Win 7 (Intel i7) machines. One is running GPU tasks the other is not. Both are running CPU tasks from multiple projects. On both machines after an MT WU starts running all CPU project task requests return "Not Requesting Tasks: no need" message in the log. On the machine running GPU tasks the GPU tasks fetch normally. This state continues even if there are no CPU tasks in the queue and there are several idle threads. I haven't waited to see if it continues after all CPU tasks are completed. Resetting the Milkyway project seems to clear up whatever is going on in BOINC Manager. Re-booting or reloading BOINC (7.0.64) and then re-booting does not. |
|
Send message Joined: 26 May 11 Posts: 32 Credit: 47,728,352 RAC: 77 |
I am moving on to other projects as I received 3 different MT tasks tonight which halted all work on my 12 core CPU when the MT task reached 9x% complete. I suspend all GPU tasks to allow the MT task to complete and then released all GPU tasks. Boinc returned to normal operations at this time including downloading more tasks. All worked well for many MT tasks cycles. the suspended MT task in every case over the last few days always had hundreds of estimated hours to go... In all cases, task work continued without incident concerning GPU work. I'll look forward to when this condition becomes fixed, and I will be back for more. |

©2026 Astroinformatics Group